数据无损压缩
本文将介绍四种两种数据无损压缩的方式(算法),上这节课已经有两个周了,除了作业就没有接触过这方面的内容,自己对数据压缩也挺感兴趣的,所以就复习总结一下,希望更多的人了解这方面的内容。
无损压缩
无损压缩这个概念顾名思义,但是惯按照例,说什么内容的时候必须要清楚自己说的是什么,通俗地说就是压缩能获得更小的体积,但是读取时能还原出和压缩前相同的数据。
两种数据无损压缩算法
无损压缩是将已有的数据格式进行压缩,为了减小数据量,往往需要改变编码格式,这个过程是通过算法实现的。这里将为大家讲解四种数据压缩算法(因为篇幅和精力有限,所以只介绍两种):
- 哈夫曼编码
- 算术编码
3. LZW 编码4. 位平面编码
当然压缩算法不止这四种,感兴趣的朋友们可以自己去了解,并且欢迎在评论区补充。
哈夫曼编码
如果你学过哈夫曼树,那么对哈夫曼编码一定不陌生,哈夫曼编码借助哈夫曼树实现。哈夫曼编码是一种游程长度编码,每一个字符使用的二进制编码长度是不一样的,相对于定长编码的,它能有效压缩数据关键在于哈夫曼编码中出现概率大的符号用长度较短的码,出现概率小的符号用较长的码,码字长度与概率严格逆序排列。
哈夫曼树
先来了解一下哈夫曼树的基础知识和重要特性,哈夫曼树又被称最优二叉树,是指对于一组带有确定权值的叶子结点所构造的具有带权路径长度最短的二叉树。听起来很难懂?让我们一个词一个词的来解释:
- 二叉树:每个节点最多只有两个孩子节点的树,如果你还不懂什么是树,可以看看前边的内容《数据结构:树》
- 带权叶子节点:权即为权重,通常用作标记一个东西的重要程度,这里可以理解为叶子节点的一个属性,拥有权重这个属性的叶子节点即为带权叶子节点。
- 带权路径长度:路径长度在《数据结构:树》中已经提到过了,指父节点到子孙节点所经历的边的条数,带权的路径长度的话就需要乘以子节点的权重,注意,路径上每一个节点的权重可能不同,所以应该每经历一条边计算一下这条边的带权路径长度,最后将经历的边的带权路径长度累加。
哈夫曼树的构造过程
最开始时,每个节点可以看作是只有一个根节点的二叉树,他们的集合叫做森林。
- 从森林中选出根节点权值最小的两棵树,创建一个新节点作为根节点,两个节点中权值较小的作为新节点的左孩子,权值较大的作为新节点的右孩子,并且向新节点赋予权值,权值的大小为两个子节点的和。这样便生成了一棵拥有三个节点的二叉树。
- 从森林中删除刚才选择的两个权值较小的节点,然后将新生成的二叉树插放入森林中。
- 重复 1-2 两个步骤,直到只有一棵树。
下面用动画演示哈夫曼树的构造过程:
链接稍后奉上
得到哈夫曼树之后我们可以根据权值计算带权叶子节点与根节点之间的带权路径,这个方法构造的带权路径的和是最小的。
从哈夫曼树到哈夫曼编码
我们已经学会了如何构造哈夫曼树,接下来可以进行哈夫曼编码了,哈夫曼编码基于哈夫曼树,所以关键就在于如何将需要编码的字符和哈夫曼树建立联系。
我们可以把字符当成节点,将字符出现的频率作为权值,所以最开始说,哈夫曼编码其实是与字符出现的频率相关的。
对文本进行哈夫曼编码的步骤如下:
- 统计文本中,各个字符出现的次数,并进行归一处理,所谓归一就是将字符出现的次数除以字符总数,得到字符在整个文本中出现的频率。
- 将这些出现过的字符转化成二叉树节点,并赋予权值,值为各自在出现的频率。
- 构造哈夫曼树。
- 给哈夫曼的树的所有结点赋予权值,左孩子节点的权值为 0,右孩子结点的权值为 1。
- 找出叶子节点对应的带权路径,从叶子节点开始,依次计算每条边的带权路径长度,并将所得的值进行拼接,就能得到该叶子节点对应的字符的哈夫曼编码。
- 按照 5 的步骤,计算所有叶子节点的哈夫曼编码,得出码表。
- 最后将每个字符用码表中的编码逐一替代即可。
哈夫曼编码的解码
哈夫曼编码进行解码是需要码表的,根据哈夫曼编码的特点,哈夫曼编码是前缀编码,即任一个字符的编码都不是另一个字符的编码的前缀,所以根据码表,逐个比对编码表,第一个匹配的编码就是对应的字符。
用 JavaScript 实现的哈夫曼编码和解码器
按照上述内容,需要先统计str中每个字符出现的频次。
1 | const charTable = new Map(); |
然后将频次转化为频率,并且转化为节点,将频率大小赋值给节点的权重。
这一步首先确定树中每个节点的结构,因最后生成的是一棵二叉树,我们需要的到叶子节点的编码,在得到编码这个过程中有两种方式:
- 节点的编码和深度优先遍历时经过的节点序列相关,在遍历查找叶子节点时记录遍历的顺序,最后将结果倒序就能得到该节点的编码。
- 通过任意方式,找到叶子节点后,向上寻找根节点,寻找的顺序即为编码序列。
如果采用第一种方式,为了便于从根节点找到子孙节点,应该采用孩子表示法或者孩子兄弟表示法。如果采用第二种方式,既要方便从子孙节点找到根节点,又要方便从根节点找到孩子节点,二叉树的几种存储结构中都不能同时满足这两个你要求,所以只能增加每个节点的数据量,同时储存父节点和子节点的信息。显然这样来回两次通过相同的路径,并且耗费更高的内存,这样是不可取的。
在这里采用的是孩子表示法。
1 | function TreeNode(weight, value) { |
确定好节点的结构之后就可以生成节点了,上面只统计了频次,我们在插入节点的时候使用一次循环同时将频次转换为频率。
1 | let totle = str.length; |
现在已经完成了数据的处理,可以开始生成哈夫曼树了。在这个过程中需要不断的对对节点列表中的节点进行排序、生成新树、移除原节点,直到节点列表中只剩一棵树。
1 | function generateHuffmanTree(nodeList) { |
执行上面的函数之后,nodeList已经是一棵哈夫曼树了,接下来需要得到码表,通过先序、中序、后序、层次遍历二叉树都能够获得码表,虽然采取层次遍历能够找到叶子节点,然后向上查找根节点,计算路径,但根据存储结构,向上查找是比较困难的,所以不建议采用层次遍历。我们遍历希望得到一条路径,优点像深度优先搜索,所以可以采用先序遍历。
1 | // 遍历节点,深度优先遍历(先序遍历),并得出码表 |
算术编码
算数编码的编码方式较为特别,大多数编码方式通过缩短编码长度或减少编码的次数来达到压缩目的,算术编码采用浮点数来表示需要压缩的内容,从某种程度上看来,储存一个浮点数确实比储存一个字符串数据占用更少的空间。
编码原理与过程
算数编码同样需要统计字符出现的频率,为每个字符划分概率区间,类似于古典概型,字符 A 的出现概率是 0.5,那么出现 AA 的概率是 0.5 × 0.5 = 0.25,不过算数计算的并不是仅概率,还要按照一定的顺序将概率放进不同长度的区间表示,最终计算的是区间。
如字符串对pass进行压缩,可以按照分以下几步进行:
先计算各字符出现的概率
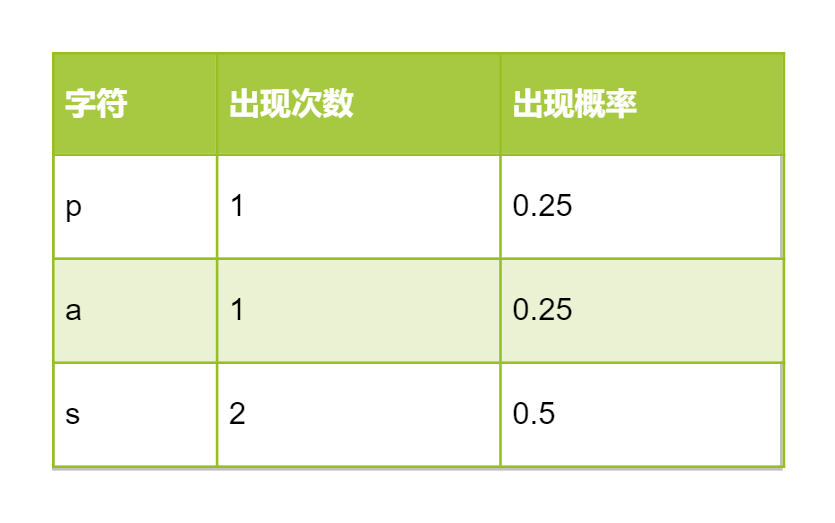
将字符分配到[0, 1)区间,各字符的区间长度为对应的概率
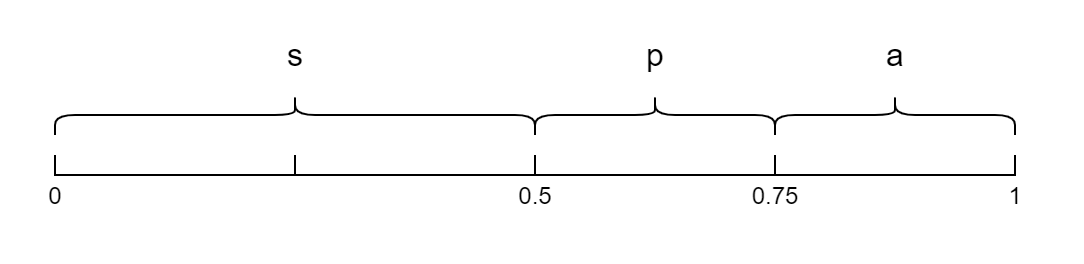
如图,因
s出现的概率为 0.5,所以区间占 0.5 长度,字符区间并没有明确的顺序,此处按照概率由大到小排列。按照字符串顺序从左往右计算,一次次增加编码字符长度,在前一次字符串的编码区间基础上上计算增加一个字符后的编码区间。
这是一个动态迭代计算的过程,简单的解释为,迭代一次计算
p字符串位于的区间,迭代第二次得出pa字符串位于的区间,迭代第三次得出pas字符串位于的区间,迭代完所有字符即可得出该字符串应该落在哪个区间,最后即可通过该区间内的任意一个数表示字符串。要得到包含 n 个字符的字符串的编码区间,必须先知道包含前 n-1 个字符的字符串的编码区间,这一点和递归思想类似。所以要计算
pa字符串的编码区间,一定是先计算了p的编码区间,所以每次计算的区间总长度是在上一次的编码区间上计算的区间长度。第一个字符在区间[0, 1)的基础上开始计算,计算
p字符所在的区间,为[0.5, 0.75),现在计算前两个字符组成字符串所在的区间,将[0.5, 0.75)区间按照上图的顺序和概率划分区间,如图所示,pa所在区间为[0.6875, 0.75)。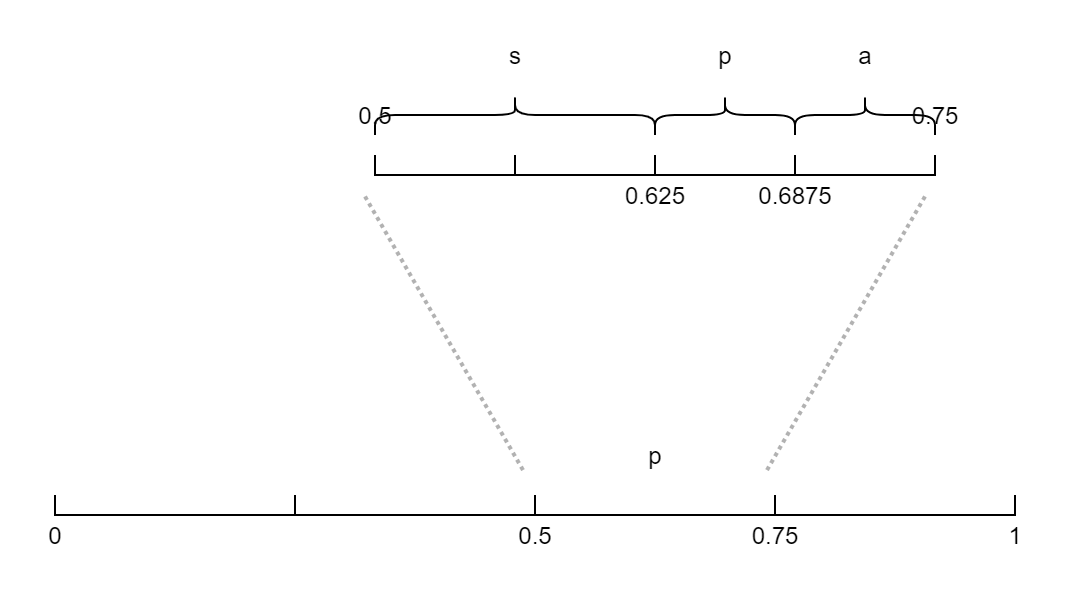
第三次将编码前三个字符的字符串
pas,将pa的区间[0.6875, 0.75),按照上述顺序和概率分配区间,得出pas的区间编码为[0.6875, 0.71875),继续上述步骤,最终得出pass的编码区间为[0.6875, 0.703125)。现在可以用[0.6875, 0.703125)中的任意一个数代表
pass,如用 0.6875 代表pass四个字符。

