Apollo-GraphQL快速上手-服务端
上次课程设计做完之后就放松了一阵子,过了这么久才来更新博客其实内心是不好受的,感觉生活缺少了什么。GraphQL 出现了很多年,一直不温不火,想尝试 GraphQL 服务器开发的朋友们可以参考一下本文,你将理解到一种 GraphQL 服务器的通用逻辑。
Apollo Server 是以 Node 为后端的 GraphQL 实现,我选择 Apollo 是因为它是一套完整的服务框架,它包括前端和后端,可拓展性强,并且 Node 也是后端开发最快的方式。
我不喜欢贴代码,我会从 0 开始搭建一个普通的 web 服务器,从创建一个 GraphQL 的 mock Server 来说明 Apollo Server 的运行逻辑,其实 GraphQL 服务器的运行逻辑也大致如此,最后接入数据库,更接近实战。
基本服务器监听
本节为搭建基础服务器而不是 GraphQL 服务器,熟练的朋友可跳过。
Apollo Server 可作为一个独立的服务器,我们可以安装 Apollo 后直接启动服务器监听,但功能它的只限于对数据的增删改查,一个服务器可能还需要如下功能:
- 模板渲染或 SSR
- 身份验证
- 文件上传
- …
为了便于拓展业务功能,我将 Apollo Server 作为 Node 服务器的中间件,你可以选择你喜欢的 Node 服务器框架,或者自己搭建 Node 服务器,我选择的是 Koa,接下来开始搭建整体架构:
安装 Koa 和 Apollo Server
1 | npm i koa-generator -g |
生成的目录如下,长的很像 MVC 架构: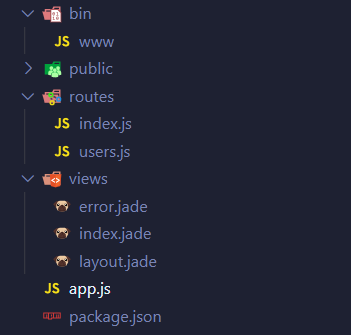
app.js 里引入了必备的库并初始化和定义路由,最终由 bin/www 引用并真正将他们使用起来。
接下来安装依赖,除了 koa-generator 生成的依赖,还需要安装apollo-server-koa和graphql,这样将 Apollo Server 作为中间件,如果你使用其他 Node 服务器,可以在这里找到适合的中间件。
开发建议
每次编辑代码之后查看更改必须要重新启动服务器,koa-generator 自动为我们安装nodemon,它能监听工作区的文件更改,进行热更新。这样的话,你需要将bin/www文件改为bin/www.js,因为nodemon不会监听没有后缀名文件的更改。
安装依赖后最后使用npm run dev就能启动服务器了,默认端口为 3000,你可以通过localhost:3000访问。
简单的 GraphQL 服务
为了方便大家理解本节内容,写这篇博客的时候我也亲自做了一遍,你可以 clone我的仓库,切换到 mock 分支查看。
1 | git clone https://github.com/KylinLee/koa-apollo-template.git |
Apollo GraphQL 由以下部分组成:
- Schema:图、结构
- Data:数据源
- Resolver:解析器
为了便于理解,先模拟一个查询书籍相关信息的 GraphQL 服务器:
Schema
Schema 相当于接口(指 API 接口),定义了客户端可以执行的操作类型,数据结构体,数据字段及类型。在 MVC 架构中,相当于模型,我的理解 Schema 是数据的入口和出口,一个请求传过来首先通过 Schema 校验,响应内容最终也会以 Schema 定义的格式返回,相当于一个模具,固定数据进出的格式。
所以新建一个model/schema目录,在目录中建立 Schema 并将其导出备用:
1 | const { gql } = require("apollo-server-koa"); |
GraphQL 中文文档中将类似于上面 Book 的结构叫做“类型”,但我认为对于编程人员将它们叫做“结构体”更容易理解。
Data
数据比较容易理解,客户端需要的内容,服务器可返回的内容就是数据。为了简化流程,便于理解,我们选择使用模拟数据,可以新建data目录,将模拟数据放在这里并导出备用:
1 | const books = [ |
Resolver
解析器的作用是将 Schema 和 Data 联系在一起,即根据客户端传来的查询语句在一大堆 Data 里边找到指定的数据,如果说放在 MVC 里边,可以作为控制器,也可以作为模型,看个人如何理解,其实 MVC 没有很严格的界定,如果你的 Resolver 除了查询数据还具有其他复杂的功能,将其定义为控制器比较合适,如果你的 Resolver 专门用于数据的查询,将其作为模型看待。我将 Resolver 放在model/resolver目录下。
现在我们可以分析一下,查询Books,需要返回一个数组,数组的每一项需要符合Book的结构,即每一项需要包含title和author字段,巧的是我们模拟的数据book正好符合Books的结构。
在开发中,这个分析很重要,请不要忽略!!!
所以我们的 Resolver 这样写:
1 | const books = require("../../data/index.js"); |
为 Schema 中对应的结构体编写同名的函数,并将这些函数作为resolvers对象的键和值,导出resolvers备用。
Resolver 进阶
其实你只编写了 Query 中 books 的解析器,books 是以 Book 为单元的数组,但我们并没有编写 Book 结构体的解析器,它还是返回了我们预期的结果。实际上 Apollo 并不是data是什么就返回什么,将data中的author改为authors,只会返回title字段内容。默认情况下,如果你没有编写某个结构体的解析器,Apollo 将会使用默认解析器,它会根据 books 的结果去验证里边的某一项是否符合 Book 解析器,最终返回符合 Book 的结果,起到了过滤的效果,了解默认解析器可以帮助你少编写代码。
Server
将三部分准备其了,接下来将这三部分接入服务器,供服务器调用,首先在www.js这个执行文件中引入这三部分,然后将他们作为选项传入 Apollo Server,最后将 Apollo Server 作为 Koa 中间件,关键代码如下:
1 | var app = require("../app.js"); |
测试结果
打开localhost:3000/graphql,进行 GraphQL 查询,GraphQL 基础这里就不讲了,既然决定用 Apollo Server 相信大家都会,测试如下: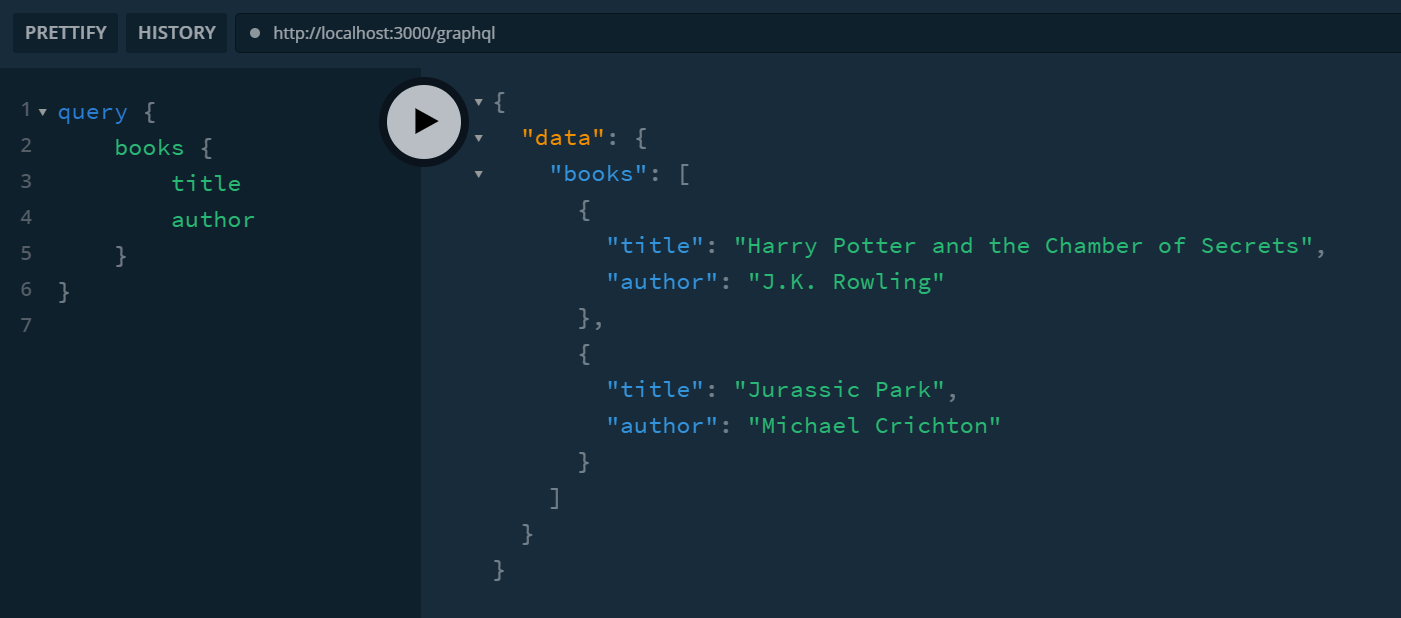
使用 MySQL 作为数据源
便于大家理解本节,你可以 clone我的仓库,切换到 mysql 分支查看。
1 | git clone https://github.com/KylinLee/koa-apollo-template.git |
通过上面的讲解你已经理解 Apollo Server 的开发流程了吧,上面这个例子中使用的是模拟的数据,是固定不变的,接下来是重头戏——接入数据库。
我是用的是 MySQL,按照官方文档,可以使用的数据源有数据库和 RESTful API,支持 RESTful API 的原因是帮助使用 RESTful API 的服务迁移到 GraphQL,我使用关系型数据库 MySQL 作为数据源。
上面的例子中我们向 ApolloServer 构造函数传递了一个配置对象,这个配置对象包含了两个内容typeDefs和resolvers。其中数据源是在 resolver 中引入的,我们也可以将数据源传入 ApolloServer 构造函数,在 ApolloServer 实例化的时候就初始化连接数据库,我们使用 Apollo 社区维护的数据源工具datasource-sql,它是基于knex的,knex是一个查询构造器,通过knex我们可以用熟悉的 JavaScript 语法去执行 SQL 查询,datasource-sql的工作是将knex包装成ApolloServer构造函数可接受的对象,让我们先安装它:
1 | npm i datasource-sql mysql --save |
然后我们需要做三部分的更改:
- 配置数据库并实例化数据源工具
- 将数据源实例传入
ApolloServer - 在 resolver 中使用数据源
配置数据库并实例化数据源工具
首先配置数据库,在data文件夹创建data/mysql.config.js:
1 | const knexConfig = { |
然后创建data/methods.js,这里边定义了数据库的操作方法供 resolver 调用,这些方法包含了你需要对数据库进行的所有操作,比如下面这段代码就是获取books表中的所有字段,相当于 SQL 语句:
1 | select * from books; |
注意:使用 knex 查询器返回的是 Promise。
1 | const { SQLDataSource } = require("datasource-sql"); |
最终实例化数据库工具的逻辑是:将数据库配置对象传入包含数据库操作方法的类,如下:
1 | const MyDatabase = require("./methods"); |
将数据源实例传入ApolloServer
通过上面的实例化之后成为了ApolloServer构造函数可接受的数据源对象,对 ApolloServer 配置做如下更改:
1 | var app = require("../app.js"); |
关键代码是第 6 行和第 11 行。
context 对象
另外我往里边传了context对象,这是非必要的,有context对象之后我们可以在 resolver 中使用他们,如上面这段代码中返回了当前请求的方法和一个uid,我们在 resolver 里边就能使用这两个变量,具体怎么使用将在下一小节中阐述。context对象是很有用的,比如通过 JWT 验证请求者身份之后,可以将记录这个身份的信息传给 resolver,接着 resolver 将这个信息作为数据库查询参数。
在 resolver 中使用数据源
使用数据源就比较简单了,和我们之前写简单的 GraphQL 服务一样,在model/resolver/index.js中写 resolver 方法:
1 | const resolvers = { |
通过前面的一系列构造,我们之前编写的数据库操作方法可以通过dataSources.db来访问,你可以使用await,也可以不使用,因为 resolver 的返回值可以是 Promise 对象,这主要取决于你的数据库操作方法是如何写的。
我们注意到每一个结构的resolver还有几个参数,resolver 可以接收四个参数,最常用的就是上面这段代码中写到的前三个参数。
第一个参数parent
上面的代码中是_source,代表上一级解析器的返回值,因为 Schema 中定义的结构体是可以嵌套的,所以出现了多级选择器的概念,GraphQL 的解析顺序是从最外层解析的,返回最外层的解析结果之后才进行下一级解析,我们可以通过这个参数获取上一级的返回值然后将这个值作为下一级的参数。
第二个参数args
上面的代码中是_args,顾名思义是参数的意思,指 GraphQL 查询中传递的参数如:
1 | query { |
假设这是查询 id 为 10 的书籍信息,那么 resolver 中可以这样写:
1 | const resolvers = { |
然后在数据库操作方法的函数中接收这个参数。
第三个参数context
第三个参数是上下文,由此可见,构造器其实是将我们的数据源db放在了上下文之中,dataSources.db则是我们的数据源,还记得之前传入ApolloServer的配置文件吗,我传入了一个 context 对象,ApolloServer 将它作为db对象的一个属性,这一点我不清楚为什么要这么设计,访问配置文件中传入的context对象通过如下方式获取:
1 | const resolvers = { |
如果你从头看完,至此相信你已经从零入门了,以上讲述的内容已经足够你开发一个功能完善的 GraphQL 服务器了,此外,不理解的话可以去 Apollo GraphQL 的官方网站看看。
如果你不想重复的配置项目,可以从我的仓库拉取代码初始化项目。

